Segmentação Semântica com Python e OpenCV
Teoria, Aplicação Real e Implementação Profunda com DeepLab v3+
- junho 7, 2025
- Diego Gualtieri
- 5:18 pm
A segmentação semântica tem emergido como uma das técnicas mais essenciais da visão computacional contemporânea, sendo amplamente adotada em aplicações críticas como carros autônomos, robótica, monitoramento ambiental, realidade aumentada e diagnóstico médico. Ao contrário da simples classificação de imagem ou da detecção de objetos por bounding boxes, a segmentação semântica se propõe a rotular cada pixel da imagem de entrada com uma classe específica, extraindo portanto um nível muito mais rico de interpretação da cena.
Neste artigo, vamos analisar em profundidade como implementar segmentação semântica com o uso da biblioteca OpenCV em Python, integrando redes neurais treinadas como o DeepLab v3+. Vamos também construir um exemplo completo com código-fonte real, discutindo os principais pontos teóricos e práticos, além de refletir sobre os desafios e o futuro dessa abordagem.
O Que É Segmentação Semântica?
Segmentação semântica é o processo de atribuir a cada pixel de uma imagem a uma etiqueta de classe com significado semântico (como “carro”, “pessoa”, “árvore”, etc).
É diferente de:
-
Classificação de imagem: classifica a imagem como um todo.
-
Detecção de objetos: localiza objetos usando bounding boxes.
-
Segmentação de instância: detecta e separa instâncias diferentes da mesma classe.
A segmentação semântica vai além: ela define com precisão onde exatamente está cada classe, pixel a pixel.
Aplicações Práticas da Segmentação Semântica
-
Veículos Autônomos: Identificação de pista, obstáculos, pedestres e semáforos.
-
Saúde: Detecção de tumores em exames de imagem (TC, RM, mamografias).
-
Agricultura de Precisão: Identificação de pragas ou doenças em plantações via drones.
-
Monitoramento Ambiental: Segmentação de rios, florestas e áreas degradadas por satélite.
-
Segurança Pública: Reconhecimento de comportamento e pessoas em ambientes urbanos.
Visão Computacional Clássica vs Aprendizado Profundo
Visão Computacional Clássica (OpenCV puro)
A segmentação pode ser feita com técnicas como:
-
Thresholding e histogramas;
-
Transformações de cor (HSV, Lab);
-
Detecção de bordas (Canny, Sobel);
-
Morfologia matemática (dilatação, erosão, etc).
Vantagens:
-
Leveza computacional.
-
Boa performance em cenários simples e com fundo homogêneo.
Limitações:
-
Sensível à iluminação, ruído e variações de textura.
-
Pouca generalização.
Visão Computacional com Deep Learning
Aqui entram arquiteturas como:
-
U-Net (2015)
-
PSPNet
-
DeepLab v3 / v3+
-
Mask R-CNN (para segmentação de instância)
Esses modelos são baseados em redes convolucionais profundas (CNNs) que aprendem automaticamente as características mais relevantes para segmentar a imagem de forma robusta e adaptativa.
Preparando o Ambiente com OpenCV e DeepLab v3+
Antes de mais nada, vamos carregar um modelo já treinado. Para isso, você pode usar a versão .pb do DeepLab v3+ (pré-treinada no COCO ou PASCAL VOC).
pip install opencv-python opencv-contrib-python numpy
Exemplo Prático: Segmentação Semântica com DeepLab v3+
1 – Importação e Leitura de Imagem
import cv2
import numpy as np
# Carregar imagem de teste
image = cv2.imread('exemplo.jpg')
original_shape = image.shape[:2]2 – Carregamento do Modelo Treinado
# Baixe e insira o modelo DeepLab v3+ (ex: 'deeplabv3_plus.pb')
net = cv2.dnn.readNetFromTensorflow('deeplabv3_plus.pb')
3 – Pré-processamento da Imagem
blob = cv2.dnn.blobFromImage(image, scalefactor=1.0, size=(513, 513),
mean=(127.5, 127.5, 127.5),
swapRB=True, crop=False)
net.setInput(blob)
4 – Inferência e Pós-processamento
output = net.forward()
output = output[0].argmax(0) # Retorna a classe com maior score para cada pixel
# Redimensionar para o tamanho original
segmentation_map = cv2.resize(output.astype(np.uint8), (original_shape[1], original_shape[0]), interpolation=cv2.INTER_NEAREST)5 – Visualização com Mapas de Cor
# Criação de colormap para representar as classes
color_map = np.random.randint(0, 255, (256, 3), dtype=np.uint8)
colored_mask = color_map[segmentation_map]
# Combinação com a imagem original
blended = cv2.addWeighted(image, 0.5, colored_mask, 0.5, 0)
cv2.imshow("Segmentação", blended)
cv2.waitKey(0)
cv2.destroyAllWindows()
Avaliando a Performance
As métricas mais comuns são:
-
Pixel Accuracy (PA): Proporção total de pixels corretamente classificados.
-
Mean Intersection over Union (mIoU): Média da interseção sobre união entre classes.
-
Class Accuracy: Acurácia para cada classe separadamente.
O DeepLab v3+, por exemplo, atinge valores de mIoU superiores a 85% em bancos como PASCAL VOC e Cityscapes, o que o torna excelente para aplicações em mobilidade urbana.
Dataset Recomendado para Treinamento Personalizado
Caso deseje treinar sua própria versão do modelo, alguns datasets recomendados:
-
PASCAL VOC 2012
-
ADE20K
-
Cityscapes
-
COCO Stuff
Você pode treinar com TensorFlow e depois converter para .pb e usar com OpenCV via cv2.dnn.
Desafios Técnicos
-
Treinamento exige GPU potente (ou TPU).
-
Rotulagem pixel-a-pixel é extremamente trabalhosa.
-
Transferência de domínio: modelos treinados em ambientes urbanos nem sempre funcionam bem em áreas rurais ou médicas sem ajustes.
Insights Técnicos
-
Prefira modelos como o DeepLab v3+ com Atrous Convolutions, que preservam a resolução espacial.
-
Use técnicas de data augmentation como rotação, flips, zoom e blur para melhorar a robustez.
-
Em ambientes críticos, combine segmentação com modelos de detecção (como YOLO) para aumentar a robustez.
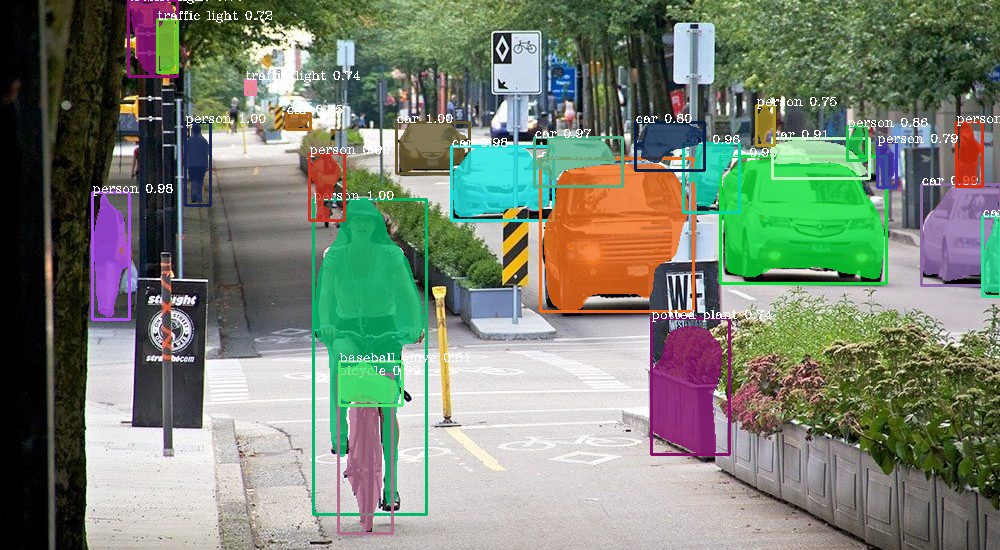
Conclusão Final
Como especialista em aplicações práticas de Visão Computacional e Inteligência Artificial, considero a segmentação semântica uma das áreas mais emocionantes e desafiadoras da IA moderna. Ela marca o momento em que as máquinas deixam de apenas ver, e passam a compreender visualmente o ambiente ao redor.
A biblioteca OpenCV, apesar de seu foco em métodos tradicionais, se reinventou ao incorporar módulos como cv2.dnn, que permitem a execução eficiente de modelos de Deep Learning diretamente em ambientes de produção. Isso abre um leque de oportunidades para projetos leves, embarcados ou com restrições de infraestrutura.
Por fim, é impossível ignorar o papel transformador que arquiteturas como U-Net, Mask R-CNN e DeepLab desempenham. Elas aproximam a computação visual da realidade cotidiana: sejam drones agrícolas que identificam pragas pixel a pixel, sejam veículos que navegam com precisão cirúrgica pelas cidades. O futuro é semântico e pixelado.
Referências
CHEN, Liang-Chieh et al. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv:1706.05587. Disponível em: https://arxiv.org/abs/1706.05587.
OpenCV Documentation – https://docs.opencv.org/
TensorFlow DeepLab v3+ – https://github.com/tensorflow/models/tree/master/research/deeplab
Dataset PASCAL VOC – http://host.robots.ox.ac.uk/pascal/VOC/
Gostou do conteúdo? Entre em contato comigo pela seção contatos. Vai ser um prazer trocar ideias com você.